Web Scraping and Crawling with Python
Lidiane Taquehara
Web Scraping and Crawling with Python
whoami

-
Brazilian immigrant, living in London
- Used to be quite active in the Python community in Brazil
-
Software engineer at Artsy
Beautiful Soup
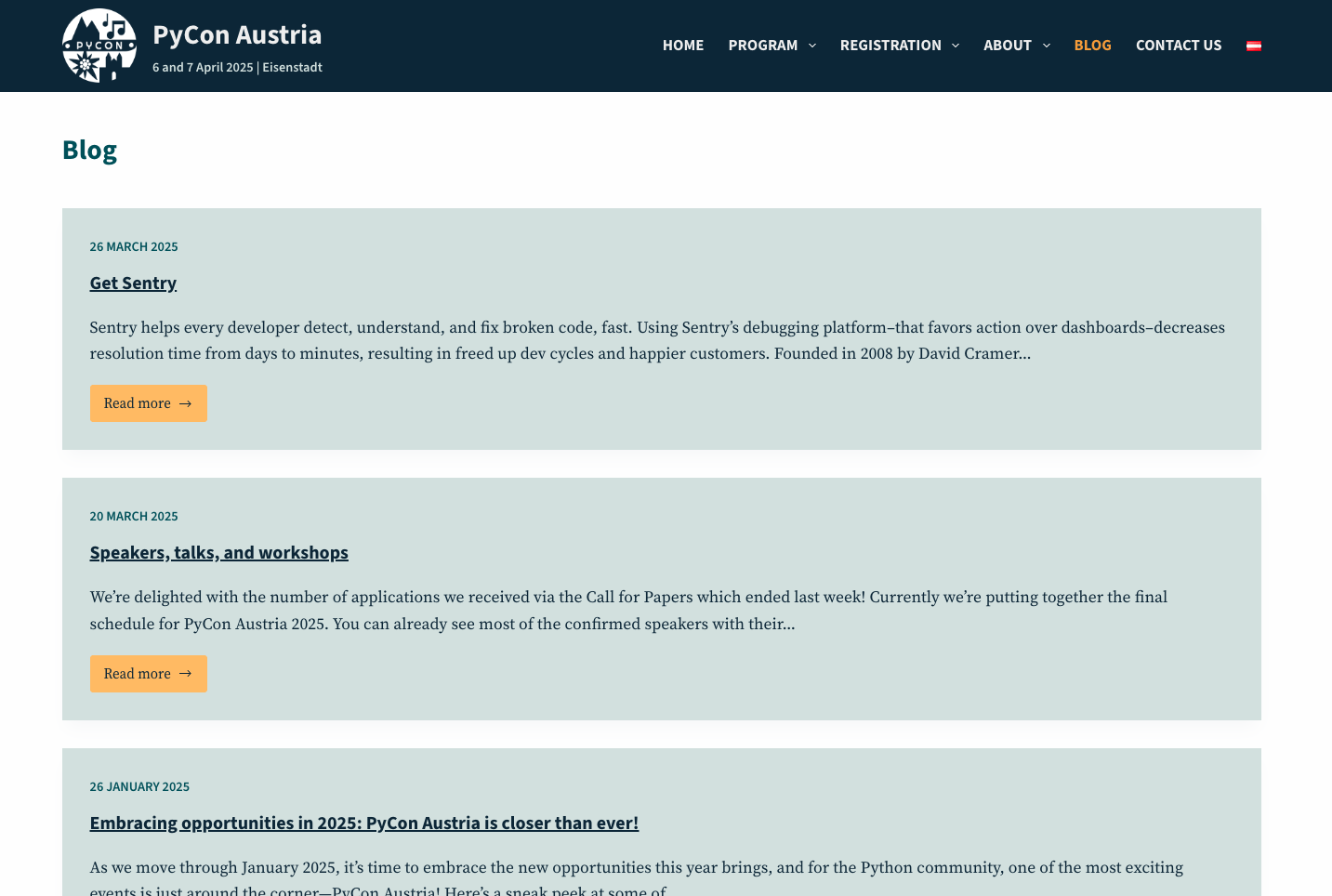
Let's scrape Pycon Austria blog
Show me the code
import requests
from bs4 import BeautifulSoup
response = requests.get('https://pycon.pyug.at/en/blog/')
soup = BeautifulSoup(response.text, 'html.parser')
for element in soup.find_all("h2"):
print(element.text)
$ python example.py
Get Sentry
Speakers, talks, and workshops
Embracing opportunities in 2025: PyCon Austria is closer than ever!
Interview with our sponsor Bitpanda
Interview with Professor Robert Matzinger of the UAS Burgenland
Interview with Thomas Mitzka
Interviews with Horst JENS and Ralf SCHLATTERBECK, PhD
Interviews with Ivana Kellyerova
call for papers (call for volunteers)
Interviews: Týna Doležalová, Lubomír Doležal
Scraping Workshops


FATEC Jundiaí, Higher Education Institution in São Paulo, Brazil
Data spread across different pages
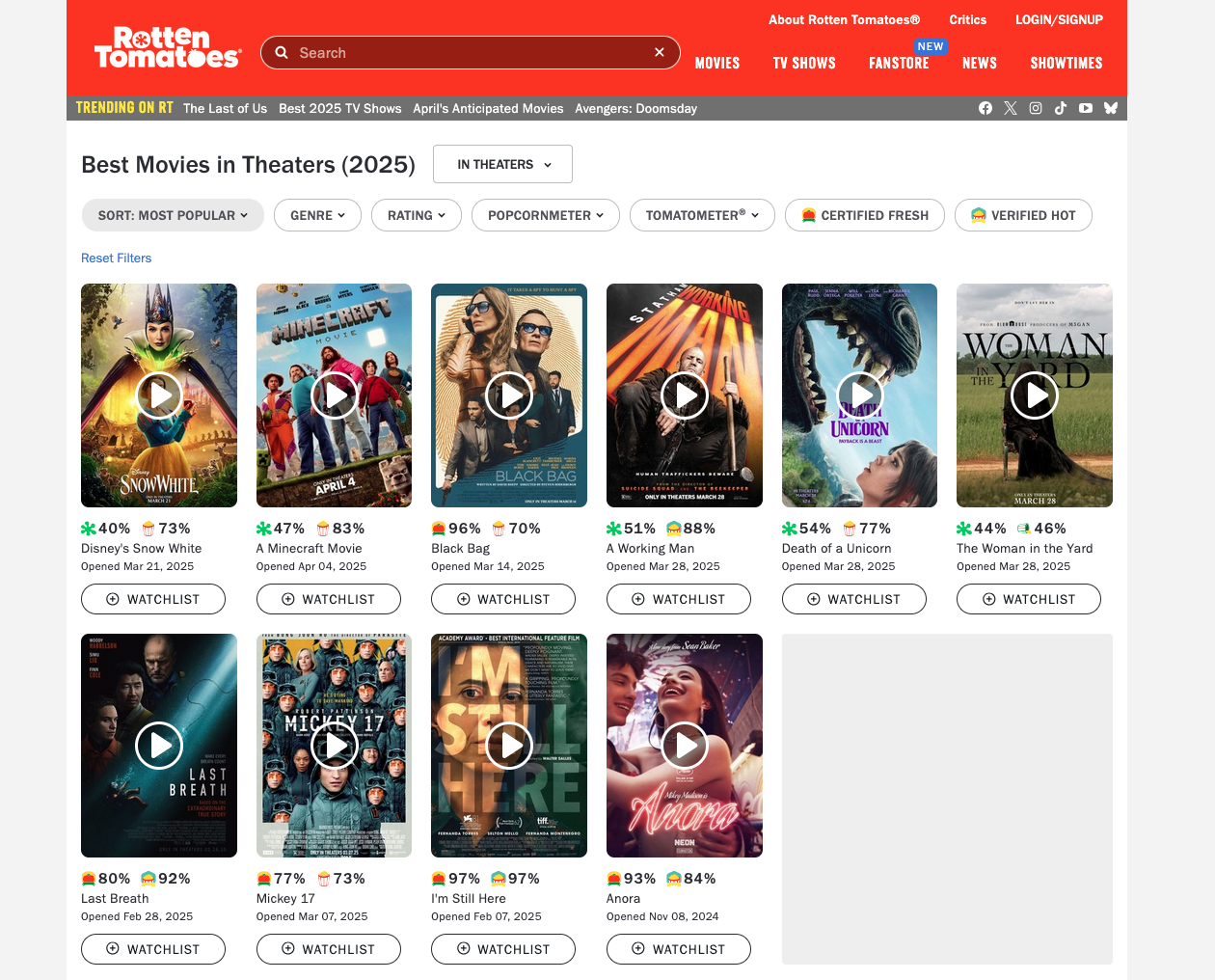
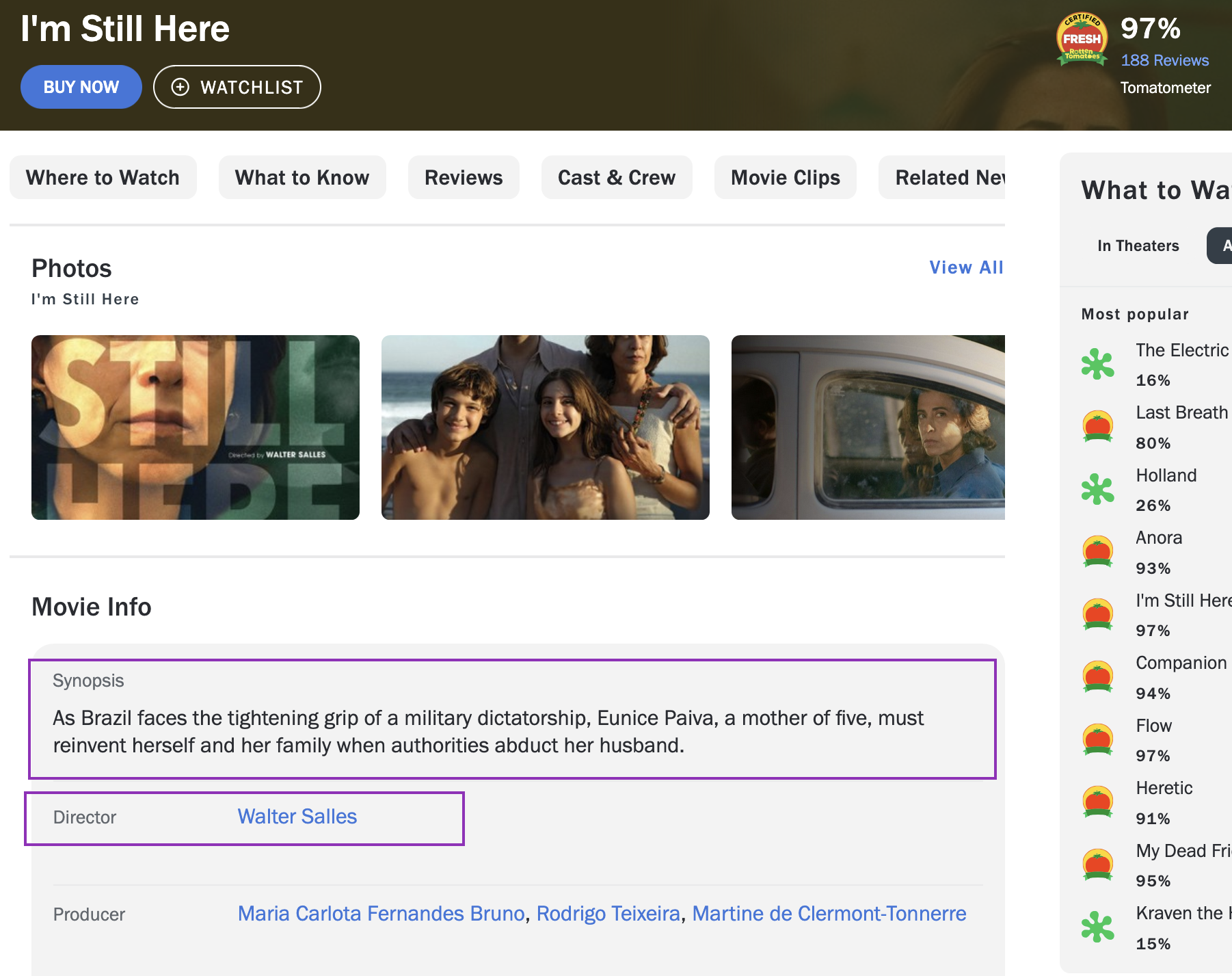
Scrapy
- Python framework focused on scraping and crawling
- Open Source
- Built on top of Twisted
Digging the code
name = 'most_popular_movies'
Define a unique identifier for the spider
start_urls = ['https://www.rottentomatoes...popular']
Specify the initial url to be hit by the spider
parse()
Manipulate the responses for each one of the requests
Data management in the cloud
Zyte (formerly Scrapinghub)
-
Creators and maintainers of Scrapy
- Zyte Managed Data (Data on Demand)
- Scrapy Cloud
Scrapy Cloud
- Host and monitor spiders in the cloud
- High availability database
Dashboard
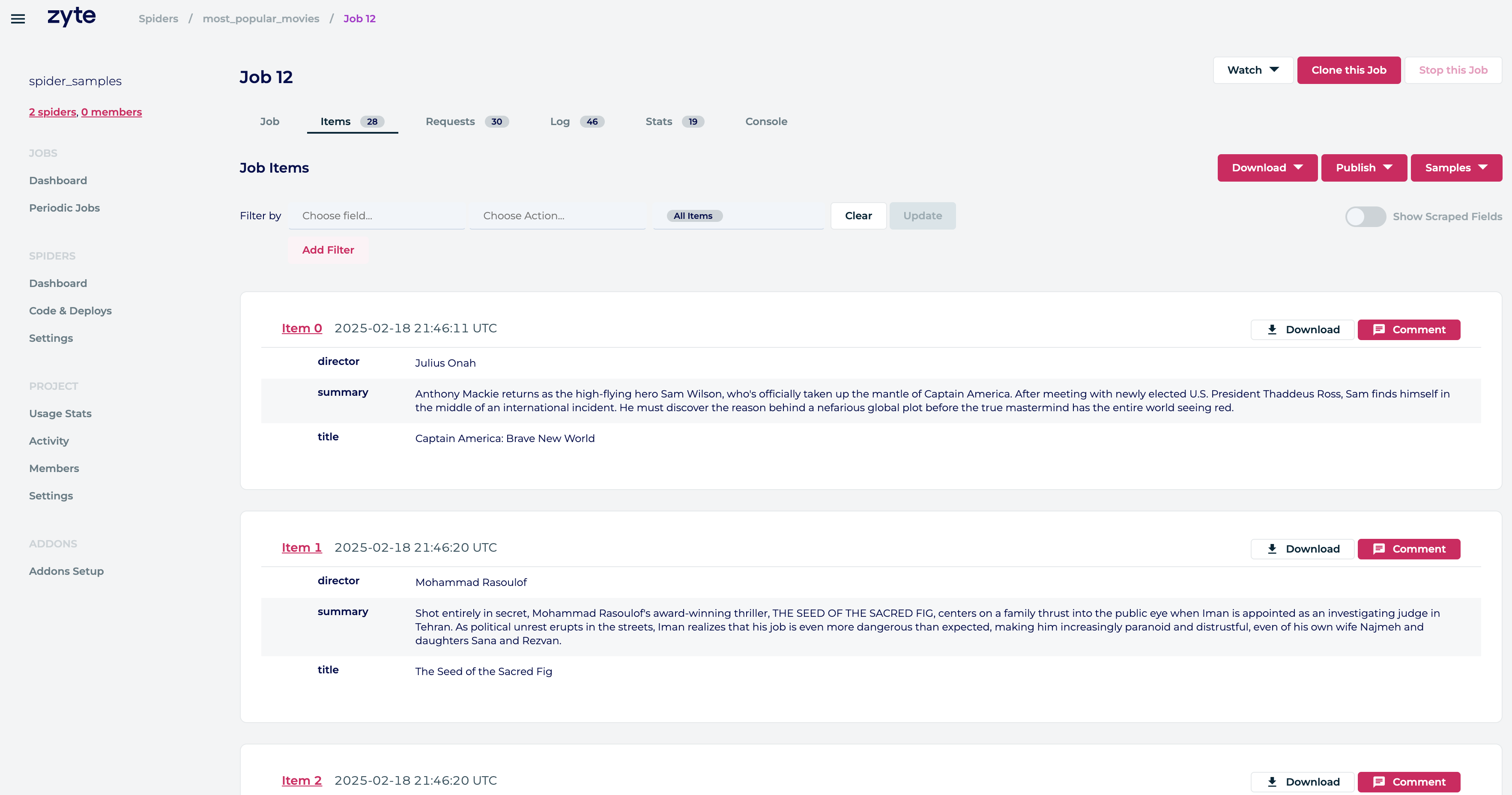
Data usage options
- Download (CSV, JSON JSON Lines, XML)
- Dataset publishing and sharing on Zyte
- Query the data via Scrapy Cloud API
Scrapy Cloud API
It enables interactions with the spiders, the collected data and cloud management
-
Endpoints:
- app.scrapinghub.com
- storage.scrapinghub.com
Real life application: Love Mondays
Thank you so much!
This presentation is available in:
https://scraping-slides.netlify.app